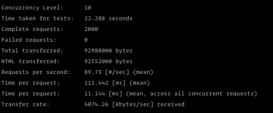
大家都知道goroutine 是 Go语言中的轻量级线程实现,由 Go 运行时(runtime)管理,Go 程序会智能地将 goroutine 中的任务合理地分配给每个 CPU。创建一个goroutine大小大概在2k左右,可以说非常的节省机器资源。
但是为什么要用池化的方式呢?机器资源总是有限的,如果创建了几十万个goroutine,那么就消耗比较大了,在一些需要对并发资源进行控制、提升性能、控制生命周期的场景中,还是需要用到协程池去处理。
今天就介绍在github用Go语言实现的有 11.5k的 Ants 协程池库的实现!
 图片
图片
初识Ants
Ants介绍
Go的协程非常轻量,但是在超高并发场景,每个请求创建一个协程也是低效的,一个简单的思想就是协程池。
Ants实现了一个具有固定容量的goroutine池,管理和回收大量goroutine,允许开发人员限制并发程序中的goroutines数量。
 图片
图片
Github地址:https://github.com/panjf2000/ants
这是在github上的截图,注意不同版本之间代码实现会略有差异。
 图片
图片
特性
Ants具有如下特性:
- • 自动管理和回收大量goroutine
- • 定期清除过期的goroutines
- • 丰富的API:提交任务,获取运行goroutine的数量,动态调整池的容量,释放池,重新启动池
- • 优雅地处理死机以防止程序崩溃
- • 高效的内存使用,甚至比Golang中的无限goroutine实现了更高的性能
- • 非阻塞机制
核心概念
- • Pool :Ants协程池核心结构
- • WorkerArray:Pool池中的worker队列,存放所有的Worker
- • goWorker:运行任务的实际执行者,它启动一个 goroutine 来接受任务并执行函数调用
- • sync.Pool:golang 标准库下并发安全的对象池,缓存申请用于之后的重用,以减轻GC的压力
- • spinLock:基于CAS机制和指数退避算法实现的一种自旋锁
运行流程图
Ants运行流程图如下:
 图片
图片
前置知识
自旋锁 spinLock
我们先了解下什么是自旋锁!
加锁的目的就是保证共享资源在任意时间里,只有一个线程访问,而自旋锁加锁失败后,线程会忙等待,直到它拿到锁。
 图片
图片
如果要实现锁的话需要实现Go 标准库sync的Locker接口
// A Locker represents an object that can be locked and unlocked.
type Locker interface {
Lock()
Unlock()
}
Ants的自旋锁是基于CAS机制和指数退避算法实现的一种自旋锁,主要利用了下面几个关键的点:
- • sync.Locker接口
- • 指数退避算法
- • sync. atomic 原子包中的方法了解
- • runtime.Gosched() 让当前goroutine让出CPU时间片
Go语言中 sync/atomic包提供了底层的原子级内存操作,可实用CAS 函数(Compare And Swap)
指数退避算法以指数方式重试请求,请求失败后重试间隔分别是 1、2、4 ...,2的n次方秒增加
我们看下具体实现代码和添加的注释:
//实现Locker接口
type spinLock uint32
//最大回退次数
const maxBackoff = 16
// 加锁
func (sl *spinLock) Lock() {
backoff := 1
//基于CAS机制,尝试获取锁
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
//执行backoff次 cpu让出时间片次数
for i := 0; i < backoff; i++ {
//使当前goroutine让出CPU时间片
runtime.Gosched()
}
if backoff < maxBackoff {
//左移后赋值 等于 backoff = backoff << 1
//左移一位就是乘以 2的1次方
backoff <<= 1
}
}
}
//释放锁
func (sl *spinLock) Unlock() {
atomic.StoreUint32((*uint32)(sl), 0)
}
Gosched()使当前goroutine程放弃处理器,以让其它goroutine运行,它不会挂起当前goroutine,因此当前goroutine未来会恢复执行。
backoff <<= 1 这段代码会有你知道什么意思吗?
这是Go语言的位运算符 << 表示左移n位就是乘以2的n次方, 而 <<= 表示左移后赋值。
代码中 backoff <<= 1 其实就是 backoff = backoff << 1,这是左移一位的结果就是 backoff = backoff * 2^1。
自旋锁执行 backoff 次让 cpu 时间片动作,次数分别是 1、2、4 ...,封顶16
Ants自旋锁逻辑用图表示如下:
 图片
图片
核心数据结构
这里简单介绍下三个核心的结构体和属性:
 图片
图片
Pool结构体
Pool就是协程池的实际结构,在下面代码中已经标记了注释。
type Pool struct {
// 协程池容量
capacity int32
// 当前协程池中正在运行的协程数
running int32
// ants 实现的自旋锁,用于同步并发操作
lock sync.Locker
// 存放一组Worker
workers workerArray
// 协程池状态 (1-关闭、0-开启)
state int32
// 并发协调器,用于阻塞模式下,挂起和唤醒等待资源的协程
cond *sync.Cond
// worker 对象池
workerCache sync.Pool
// 等待的协程数量
waiting int32
// 回收协程是否关闭
heartbeatDone int32
// 闭回收协程的控制器函数
stopHeartbeat context.CancelFunc
// 协程池的配置
options *Options
}
这里对几个配置着重讲一下:
workerCache :这是sync.Pool类型,主要作用保存和复用临时对象,减少内存分配,降低 GC 压力,在Ants中是为了缓存释放的 Worker 资源
options:可配置化过期时间、是否支持预分配、最大阻塞数量、panic 处理、日志,这里是通过函数式选项模式进行实现的
goWorker
goWorker 是运行任务的实际执行者,它启动一个 goroutine 来接受任务并执行函数调用,这个协程是一个长期运行不会被主动回收的。
type goWorker struct {
//goWorker 所属的协程池
pool *Pool
//接收实际执行任务的管道
task chan func()
//goWorker 回收到协程池的时间
recycleTime time.Time
}
WorkerArray
workerArray 是一个接口( interface),其实现包含 stack 栈版本和 queue 队列两种实现。
 图片
图片
它定义了几个通用和用于回收过期 goWorker 的 api
type workerArray interface {
// worker 列表长度
len() int
// 是否为空
isEmpty() bool
// 插入一个goworker
insert(worker *goWorker) error
// 从WorkerArray获取可用的goworker
detach() *goWorker
// 清理pool.workers中的过期goworker
retrieveExpiry(duration time.Duration) []*goWorker
// 重置,清空WorkerArray中所有的goWorker
reset()
}
核心方法
这是核心实现代码的走读部分,基本上都有进行了注释,看起来可能会有点不怎么理解,多看两遍就好,相信我 !
创建Pool
创建Pool其实就是New一个Pool实例,对Pool中结构体的属性进行初始化、加载一些配置,这种方式很常见,大家可以注意观察积累。
 图片
图片
代码实现和注释如下:
func NewPool(size int, options ...Option) (*Pool, error) {
//读取一些自定义的配置
opts := loadOptions(options...)
...
// 创建 Pool 对象
p := &Pool{
capacity: int32(size),
lock: internal.NewSpinLock(),
options: opts,
}
// 指定 sync.Pool 创建 worker 的方法
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
// 初始化Pool时是否进行内存预分配
// 区分workerArray 的实现方式
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
// 预先分配固定 Size 的池子
p.workers = newWorkerArray(loopQueueType, size)
} else {
// 初始化不创建,运行时再创建
p.workers = newWorkerArray(stackType, 0)
}
p.cond = sync.NewCond(p.lock)
// 开启一个goroutine清理过期的 worker
go p.purgePeriodically()
return p, nil
}
workerChanCap:确定工作程序的通道是否应为缓冲通道,当获取给GOMAXPROCS设置的值等于1时表示单核执行,此时的通道是无缓冲通道,否则是有缓冲通道,且容量是1。
这里讲的是默认未进行预分配,采用 workerStack 栈实现workerArray的初始化。
清理过期goWorker
在初始化好Pool结构属性后,会开启一个goroutine清理过期的 worker。
怎么判定goroutine是过期的?
Ants过期的定义是:每个 goWorker的 recycleTime 加上用户配置的过期时间 Pool.options.ExpiryDuration 小于 time.Now() 时即认为该协程已过期。
我们看下具体流程
func (p *Pool) purgePeriodically(ctx context.Context) {
// ExpiryDuration 默认是1s
heartbeat := time.NewTicker(p.options.ExpiryDuration)
...
for {
select {
case <-heartbeat.C:
case <-ctx.Done():
return
}
// pool关闭
if p.IsClosed() {
break
}
// 从 workers 中获取过期的 worker
p.lock.Lock()
expiredWorkers := p.workers.retrieveExpiry(p.options.ExpiryDuration)
p.lock.Unlock()
// 清理过期的worker
for i := range expiredWorkers {
expiredWorkers[i].task <- nil
expiredWorkers[i] = nil
}
// 唤醒所有等待的线程
if p.Running() == 0 || (p.Waiting() > 0 && p.Free() > 0) {
p.cond.Broadcast()
}
}
}
清理流程如下:
- 1. 取出过期的goWorker
- 2. 通知 goWorker 退出,方式是向过期 goWorker 的 task channel 发送一个 nil
- 3. 接收值为 nil 的任务后goWorker会退出
- 4. 所有工作程序都已清理完毕,可能这时还有 goroutine 阻塞在cond.Wait上,会调用 p.cond.Broadcast() 唤醒这些 goroutine
Submit任务提交
在初始化完成Pool之后,就需要往池中提交带执行任务了,Pool提供了 Submit 方法,提供外部发起提交任务的接口。
func (p *Pool) Submit(task func()) error {
// pool是否关闭
if p.IsClosed() {
return ErrPoolClosed
}
var w *goWorker
// 尝试获取空闲的goWorker
if w = p.retrieveWorker(); w == nil {
return ErrPoolOverload
}
// 发送到 goWorker的channel中
w.task <- task
return nil
}
获取可用goWork
Submit方法内部调用 pool.retrieveWorker 方法并尝试获取一个空闲的 goWorker,如果获取成功会将任务发送到goWorker的channel类型task中。
func (p *Pool) retrieveWorker() (w *goWorker) {
//创建一个新的goWorker,并执行
spawnWorker := func() {
//实例化 worker
w = p.workerCache.Get().(*goWorker)
// 运行
w.run()
}
// 加锁
p.lock.Lock()
// 从workers 中取出一个 goWorker
// workerStack 实现了p.workers的方法
w = p.workers.detach()
if w != nil {
p.lock.Unlock()
// Pool容量大于正在工作的 goWorker 数量)
//则调用 spawnWorker() 新建一个 goWorker
} else if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
p.lock.Unlock()
spawnWorker()
} else {
// options设置了非阻塞选项,直接返回 nil
if p.options.Nonblocking {
p.lock.Unlock()
return
}
retry:
//option设置了最大阻塞队列,当前阻塞等待的任务数量已经达设置上限,直接返回 nil
if p.options.MaxBlockingTasks != 0 && p.Waiting() >= p.options.MaxBlockingTasks {
p.lock.Unlock()
return
}
...
var nw int
//如果正在执行的worker数量为0时,则重新创建woker
if nw = p.Running(); nw == 0 {
p.lock.Unlock()
spawnWorker()
return
}
//p.workers中获取可用的worker
//执行开头创建的spawnWorker
if w = p.workers.detach(); w == nil {
if nw < p.Cap() {
p.lock.Unlock()
spawnWorker()
return
}
goto retry
}
p.lock.Unlock()
}
return
}
看完注释后理一理retrieveWorker的执行逻辑:
- 1. 声明一个spawnWorker,从对象池 workerCache 中获取 goWorker
- 2. 尝试从 workers 中取出可用的 goWorker
- 3. 如未达到协程池的容量限制,获取并启动 spawnWorker(goWorker)
- 4. 如何用户设置了非阻塞选项,直接返回空的goWorker
- 5. 如果正在执行的goWorker 的数量等于0,调用 spawnWorker()
- 6. 未获取到goWorker,并且Pool容量未满,同样调用 spawnWorker()
spawnWorker() 是一个创建和运行goWorker的函数,为后面获取不到goWorker时先进行预创建goWorker
任务执行
任务执行就是开启了一个协程,然后执行goWorker中channel的任务task。
func (w *goWorker) run() {
// pool的running 加 一
w.pool.addRunning(1)
go func() {
defer func() {
...
if p := recover(); p != nil {
//处理捕获的panic
}
w.pool.cond.Signal()
}()
//任务执行
for f := range w.task {
if f == nil {
return
}
f()
//执行完后回收worker
if ok := w.pool.revertWorker(w); !ok {
return
}
}
}()
}
goWorker放回pool
我们知道实际用户的任务是绑定在goWorker上的, 在执行完任务之后Ants,会将该goWorker放回到workers结构的items数组中(协程池)。
func (p *Pool) revertWorker(worker *goWorker) bool {
if capacity := p.Cap(); (capacity > 0 && p.Running() > capacity) || p.IsClosed() {
p.cond.Broadcast()
return false
}
// 重置空闲计时器,用于判定过期
worker.recycleTime = p.nowTime()
p.lock.Lock()
...
// 调用works的insert方法放回Pool
err := p.workers.insert(worker)
if err != nil {
p.lock.Unlock()
return false
}
// p.cond.Signal() 唤醒一个可能等待的线程
p.cond.Signal()
p.lock.Unlock()
return true
}
原文地址:https://mp.weixin.qq.com/s/fZpPkG-C0wZ5Z45H2aUxAA



也不报错的解决方案")